基于WSL搭建Hadoop伪分布式
WSL使用指南
1.开启WSL
开启WSL第一步是 启动Windows Subsystem for Linux功能,有两种方法实现。
1.1.通过命令行
以 管理员身份运行 PowerShell。右键单击屏幕左下角 “开始”菜单,找到“Windows PowerShell(管理员)”并运行。
执行以下命令
1 | Enable-WindowsOptionalFeature -Online -FeatureName Microsoft-Windows-Subsystem-Linux |
安装完成后重启即可
1.2.通过控制面板
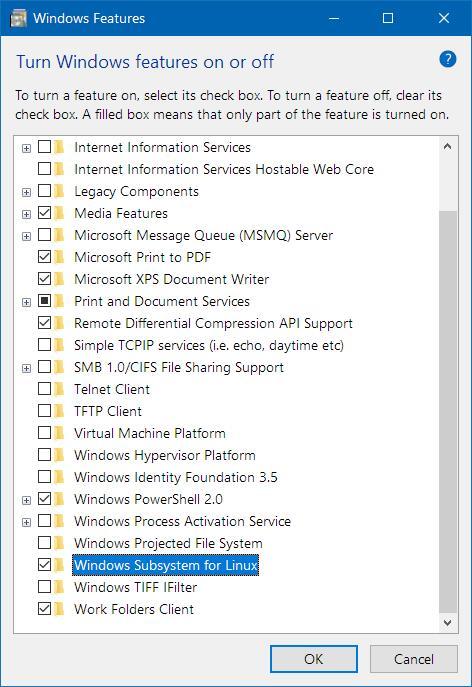
打开控制面板——“程序”——“启用或关闭Windows功能”——勾选“适用于Linux的Windows子系统”——“确定”。
点击确定后重启即可
2.安装LINUX子系统
推荐打开微软商店搜索”LINUX”,点击安装Ubuntu
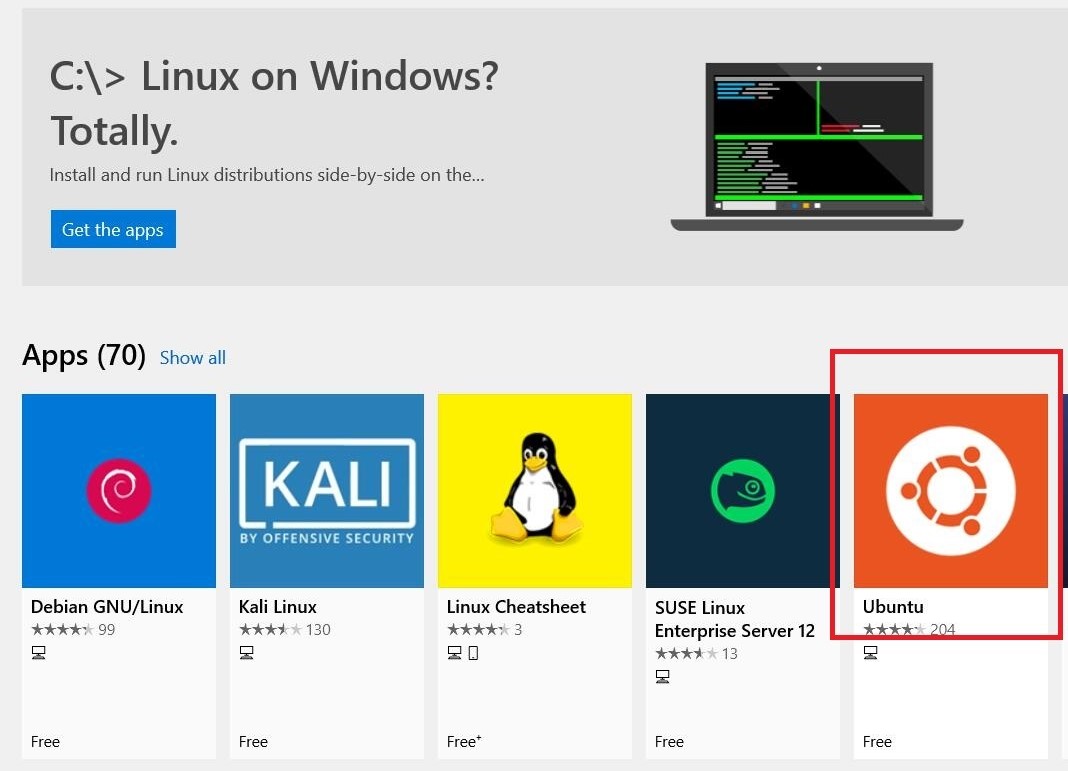
可安装多种Linux发行版,不冲突。
安装完成后设置用户名和输入密码(两次)即可
3.启动WSL
- 直接从开始菜单点击图标运行
- 启动CMD,输入
bash即可运行
4.注意事项
4.1.端口冲突(备用)
WSL和Win10共享同一套端口,如果出现两者监听同一个端口的情况,Windows主系统的程序拥有更高的优先级。可以考虑修改WSL中SSH的监听端口。
修改/etc/ssh/sshd_config配置中相应条目如下
1 | sudo vim /etc/ssh/sshd_config |
1 | Port 2222 # 将22改为2222 |
重启sshd服务
1 | sudo service ssh restart |
4.2.文件系统
WSL和Windows主系统之间的文件系统可以互相访问
Linux发行版的数据文件夹在 C:\Users\{你的用户名}\AppData\Local\Packages\{Linux发行版包名}\LocalState\rootfs路径内,rootfs文件夹为WSL的根目录。
也可直接映射在此电脑中:
- 在win10的资源管理器内输入
\\wsl$ - 右键映射为网络驱动器即可在此电脑中看到
注意:在Windows下对WSL文件修改可能会造成权限错误
5.尾巴
更多信息可参阅微软官方文档
Hadoop伪分布式配置
1.JDK配置
进入Java Downloads | Oracle下载页面。(建议使用JDK1.8)
根据Linux系统的位数选择要下载的压缩包。
执行命令:
1 | getconf LONG_BIT |
如果显示32,则是23位的Linux系统,如果显示64,则是64位的Linux系统。这里是64位的,所以下载Linux x64
下载需要注册Oracle的账号,注册邮箱推荐网易邮箱。
注:JDK8或者JDK1.8是由于自从JDK1.5/JDK5命名方式改变后遗留的新旧命令方式问题。所以JDK8和JDK1.8等价。
1.1.解压安装
创建安装目录
1
mkdir /usr/local/java/
将压缩包直接移动到该目录下
解压缩到安装目录
1
sudo tar -zxvf jdk-8u231-linux-x64.tar.gz -C /usr/local/java/ #注意下载的jdk版本
解压缩以后,进入/usr/local/java/目录后,你会发现多一个目录,它就是JDK所在目录。JDK版本不同,这个目录名有所不同,这里是jdk1.8.0_231,那么完整路径就是**/usr/local/java/jdk1.8.0_231**,记住这个路径,下面会用到。
1.2.设置环境变量
编辑变量
1
sudo vim ~/.profile
编辑模式下输入配置的环境变量
1
2
3
4
5set java1.8
export JAVA_HOME=/usr/local/java/jdk1.8.0_231
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=.:${JAVA_HOME}/bin:$PATH使环境变量生效
1
source ~/.profile
查看Java版本信息
1
java -version
得到输出结果
1
2
3java version "1.8.0_231"
Java(TM) SE Runtime Environment (build 1.8.0_231-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.231-b12, mixed mode)
2.SSH配置
Ubuntu已经自带了SSH client,还需要安装SSH server
1
sudo apt-get install openssh-server
手动启动sshd
1
sudo service ssh restart
接下来进入ssh配置文件并修改一些设置
1
sudo vim /etc/ssh/sshd_config
允许root用户以任何认证方式登录
1
2ListenAddress 0.0.0.0
PermitRootLogin yes执行
1
ssh localhost
启动后,可以通过如下命令查看服务是否正确启动
1
ps -e | grep ssh
输出以下结果说明ssh启动成功
1
2
3
4286 ? 00:00:00 sshd
699 tty1 00:00:00 ssh
700 ? 00:00:00 sshd
768 ? 00:00:00 sshd
2.1.ssh localhost报错处理
如果遇到诸如ssh: connect to host localhost port 22: Connection refused之类的错误,请运行以下命令:
1 | sudo apt-get install ssh |
安装成功后重新启动ssh
1 | sudo service ssh restart |
执行
1 | ssh localhost |
连接成功则输出系统信息
3.Hadoop配置
3.1.下载Hadoop
从Apache Hadoop下载hadoop-3.2.2.tar.gz直接拖拽到
1
C:\Users\用户名\AppData\Local\Packages\CanonicalGroupLimited.Ubuntu18.04onWindows_79rhkp1fndgsc\LocalState\rootfs\usr\local
重启电脑后在WSL终端
/user/local/下执行1
sudo tar -xvf hadoop-3.2.2.tar.gz
查看Hadoop是否安装成功,在
/usr/local/hadoop-3.2.2目录下执行1
./bin/hadoop version
得到输出结果

给与读写权限
1
sudo chmod -R 777 /usr/local/hadoop-3.2.2
3.2.配置伪分布式环境
配置Hadoop伪分布式环境需要修改/usr/local/hadoop-3.2.2/etc/hadoop/文件夹下的hadoop-env.sh、core-site.xml、hdfs-site.xml 、maprep-site.xml、yarn-site.xml
- 修改
hadoop-env.sh1
sudo vim hadoop-env.sh
1 | export JAVA_HOME=/usr/local/java/jdk1.8.0_231 |
- 修改
core-site.xml1
sudo vim core-site.xml
1 | <configuration> |
- 修改
hdfs-site.xml1
sudo vim hdfs-site.xml
1 | <configuration> |
- 修改
maprep-site.xml1
sudo vim maprep-site.xml
1 | <configuration> |
- 修改
yarn-site.xml1
sudo vim yarn-site.xml
1 | <configuration> |
4.启动Hadoop
在
hadoop-3.2.2目录下执行命令将NameNode格式化(第一次启动时执行),格式化成功会在/usr/local/hadoop-3.2.2/tmp创建dfs文件夹。1
2cd /usr/local/hadoop-3.2.2
./bin/hdfs namenode –format在
hadoop-3.2.2/sbin目录下执行启动命令打开所有进程1
./start-all.sh
在
hadoop-3.2.2/sbin目录下执行启动命令打开工作历史日志服务进程1
./mr-jobhistory-daemon.sh start historyserver
执行
JPS查看进程情况,显示七个进程说明成功1
2
3
4
5
6
712436 SecondaryNameNode
13397 ResourceManager
11960 NameNode
14138 JobHistoryServer
13771 NodeManager
14205 Jps
12175 DataNode
5.通过Web页面查看管理进程
- 查看 HDFS 的 NameNode
注:Hadoop2.x为 http://localhost:50070
- 查看 YARN 的 ResourceManager
- 查看工作历史日志服务进程