一、中文分词技术
词是中文语言理解中最小的能独立语言的语言单位。
中文分词上指将汉字序列按照一定规则逐个切分为词序列的过程。由于中文中词与词之间没有明确的分隔标志,因此中文分词需要依靠一定技术和方法找寻类似英文中空格作用的分隔符。
1.基于规则分词
基于规则分词是中文分词最先使用的方法,常见的方法有正向最大匹配法、逆向最大匹配法等。
基于规则的分词方法是一种比较机械的分词方法,其基本思想上讲待分词语句中的字符串和词典逐个匹配,找到匹配的字符串则切分,不匹配则减去边缘的某些字符,从头再次匹配,直至匹配完毕或者没有匹配到词典中的字符串而结束。
1.1.正向最大匹配法
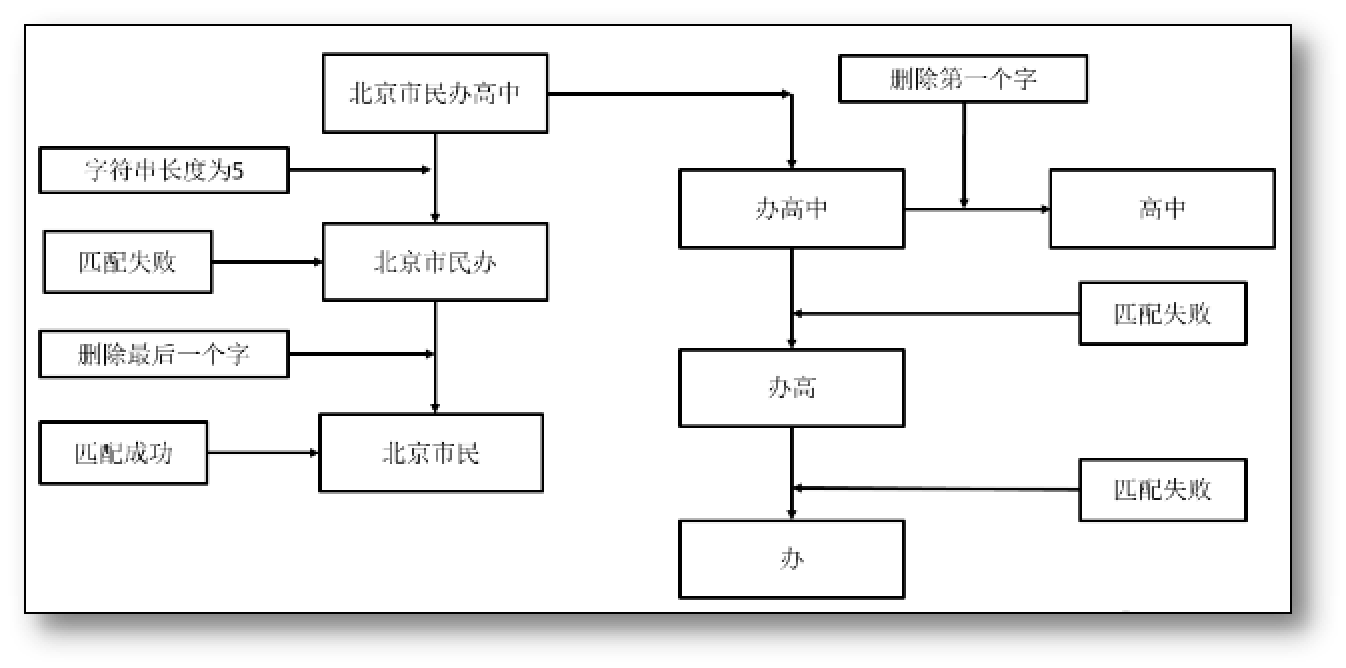
假设有一个待分词的中文文本和一个分词词典,词典中最长字符串的长度为l。从左至右切分待分词文本的前l个字符,然后在词典中查找是否有一样的字符串。
若匹配失败则删去该字符串的最后一个字符,仅保留下前l-1个字符,继续匹配这个字符,以此类推。
若匹配成功,那么被切分下来的第二个文本成为新的待分词文本,重复以上操作直至匹配完毕。
若一个字符串全部匹配失败,那么逐次删去第一个字符,并重复上述操作。
1
2
3
4
5
6
7
| #dic.utf8
北京市民
民办高中
天安门广场
北京市
高中
的
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| def get_dict():
dictionary = []
dic_path = './data/dic.utf8'
for line in open(dic_path, 'r', encoding='utf-8-sig'):
line = line.strip()
if not line:
continue
dictionary.append(line)
return list(set(dictionary))
|
1
2
3
4
5
6
7
8
9
10
11
| def calculate_max_length(dictionary):
max_length = 0
word_length = []
for word in dictionary:
word_length.append(len(word))
return max(word_length)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| def MM(text):
dictionary = get_dict()
max_length = calculate_max_length(dictionary)
global MM_cut_list
MM_cut_list = []
text_length = len(text)
while text_length > 0:
divide = text[0:max_length]
while divide not in dictionary:
if len(divide)==1:
break
divide=divide[0:len(divide)-1]
MM_cut_list.append(divide)
text = text[len(divide):]
text_length = len(text)
MM('北京市民办高中')
|
1.2.逆向最大匹配法
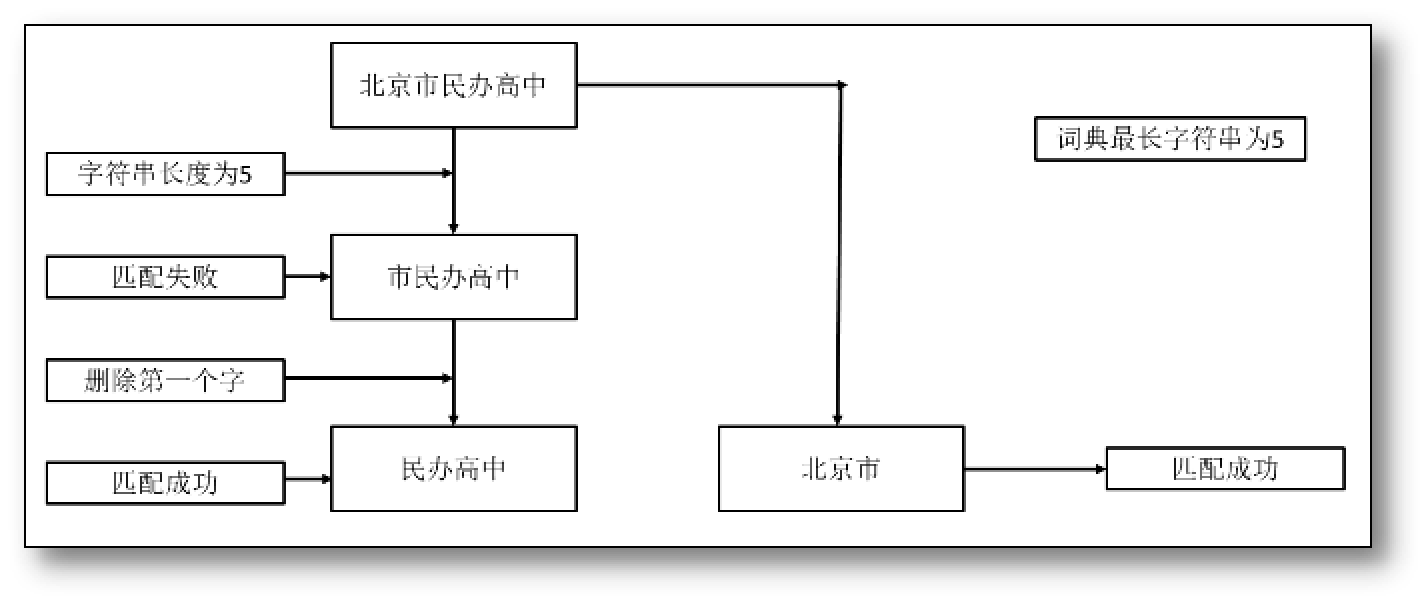
逆向最大匹配法跟正向最大匹配法原理相反。从右至左匹配待分词文本后的L个字符串,在词典中查找是否有一样的字符串。
若匹配失败,仅留下待分词文本的后L-1个词,继续匹配这个字符串,以此类推。
若匹配成功,则被切分下来的第一个文本序列成为新的待分词文本,重复以上操作直至匹配完毕。
若一个词序列完全匹配失败,则逐次删去最后一个字符,并重复上述操作。
1
2
3
| for i in range(10,0,-1):
print(i)
|
1
2
3
| for i in range(10,1):
print(i)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| def RMM(text):
dictionary = get_dict()
max_length = calculate_max_length(dictionary)
global RMM_cut_list
RMM_cut_list = []
text_length = len(text)
while text_length > 0:
match = False
for i in range(max_length, 0, -1):
if text_length - i < 0:
continue
new_word = text[text_length - i:text_length]
if new_word in dictionary:
RMM_cut_list.append(new_word)
text_length -= i
match=True
break
if not match:
text_length -= 1
RMM_cut_list.reverse()
RMM('北京市民办高中')
|
1.3.双向最大匹配法
双向最大匹配法的基本思想上讲正向最大匹配法和逆向最大匹配法的结果进行对比,选取两种方法中分词数量较少的结果作为切分结果。
如果分词数量一致,再判断分词结果是否完全相同,如果分词结果相同,可以返回任何一个;如果分词结果不同,返回单字数比较少的那个。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
|
text = '北京市民办高中'
MM(text)
RMM(text)
cut_words_list = []
MM_cut_list_size = len(MM_cut_list)
RMM_cut_list_size = len(RMM_cut_list)
if MM_cut_list_size != RMM_cut_list_size:
if MM_cut_list_size > RMM_cut_list_size:
cut_words_list = RMM_cut_list
else:
cut_words_list = MM_cut_list
else:
fmm_single = 0
bmm_single = 0
isSame = True
for i in range(len(RMM_cut_list)):
if isSame and MM_cut_list[i] not in RMM_cut_list:
isSame = False
if len(MM_cut_list[i]) == 1:
fmm_single += 1
if len(RMM_cut_list[i]) == 1:
bmm_single += 1
if isSame:
cut_words_list = MM_cut_list_size
if fmm_single > bmm_single:
cut_words_list = RMM_cut_list
else:
cut_words_list = MM_cut_list
print(cut_words_list)
|
二、尾巴